
Continuous Integration and Automated Testing
Finally!
Continous integration and automated testing have both been discussed for a very long time by the team, so it’s great to finally find the time to put it all into action and make it happen. Especially because as a small team, our resources are very limited - we don’t have a dedicated QA team (or even person for that matter), so the bulk of the testing falls on us, the engineers. Unless we can do this automatically somehow.
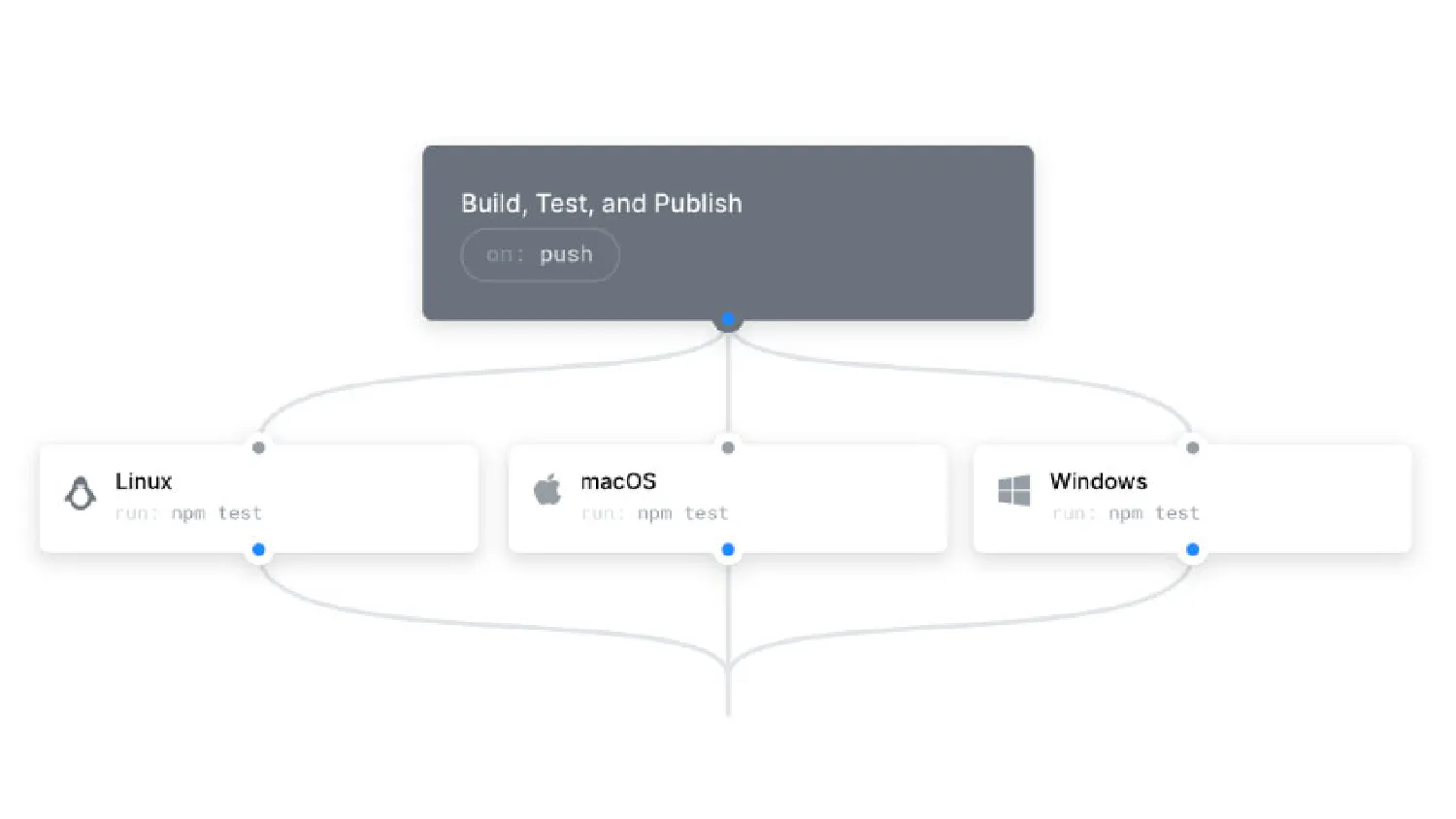
I see this entire system as two discrete phases: Building and Testing. As of writing this, we have the Building phase up and running for all supported platforms, with Testing planned for the near-ish future. Let’s talk about these briefly.
Building
Phase 1 is building. Put simply - when code changes are made, it would be useful to see if those changes correctly build on all supported platforms in all configurations. This is a super-easy black and white test that every single project, at least those that are “serious” and worked on by more than one person, should utilise. It either compiles or it doesn’t, it’s not hard to put together.
The real benefit comes when you have more than one compiler or platform that needs to build your project. If someone commits code that builds fine on Windows using MSVC, but didn’t bother testing it using Clang, it might not build using the latter (as is often the case in our experience). Eventually someone (usually Emily) would pull the latest changes and try and work on something on Linux, only to find that the engine doesn’t even compile. Not great.
But aside from that, even on a single platform sometimes we forget to test ALL configurations (eg. Debug/Release/Dist). Sometimes a code refactor, such as a variable rename, can mean that an assert no longer compiles since it references a non-existing variable - but since we usually run the engine in Release (Debug is much too slow), unless you explicitly try compiling in Debug you would never see that assert not compile, since asserts are stripped from non-Debug builds.
I put this automatic-building situation together using GitHub Actions. It’s really simple and quite powerful - you can setup a self-hosted runner that will run a particular workflow you specifiy, whenever a specified event occurs. I made a video on how I put this together with many more details:
I set this up for Windows initially, using a physical QA PC that we had in the office, but of course we wanted to build on Linux as well. I’m planning to set up a physical Linux PC in the office, but in the meantime I quickly spun this up using a Hostinger VPS - super easy to grab a VPS and have it run as a self-hosted runner, as long as building is all you’re doing (since running would require a GPU for most useful cases). Here’s a video on the Linux VPS setup:
Running
Phase 2 is running. Once you’ve successfully built, you need to run! This makes sense since many bugs are only evident during runtime - it’s easy to get the engine to compile, but of course there will be plenty of things that don’t quite work. We have some automated test runners in the works, but this is not part of our continuous integration pipeline just yet.
Hazel’s test runner will load a special Hazel QA project we have, and run every scene within that project automatically, switching every scenes every x seconds. The Hazel QA project is a special testing project we’ve put together, which functions a bit like a game (as in, it builds into an application like a normal game, or any other Hazel project would). The project contains a collection of scenes that have been created to test basically every feature we have. There are series of “unit” tests (in quotes because many of them aren’t exactly a single unit of work) which test something in the C# API for example and validate against the expected result, providing us with a report. Then there are also manual test scenes which a human has to look at, to make sure everything visually appears in order. These can be automated in the future too, by comparing frames to existing correct ones and determining divergence.
Once we have 100% coverage (if we can get there), and a way to test this automatically, we should be able to make Hazel significantly more stable going forward.